
Barrelfish OlympOS
Barrelfish OS variant implementation for Pandaboard ES. A group project in Advanced Operating Systems (Prof. Roscoe, Systems Group, ETH Zürich).
![]()
This intensive 3 month project allowed me to get lots of hands-on experience how an operating system creates and maintains the three main functionalities (OS lectures by Prof. Hoefler, SPCL, ETH Zürich):
- Referee (fair, secure and efficient resource management)
- Illusionist (virtualization)
- Glue (provide abstractions over the hardware)
Barrelfish
Barrelfish is a research operating system that uses a fundamentally different architecture than commonly used OS like macOS, Windows, Linux with monolithic or hybrid kernels. In Barrelfish, a lightweight exokernel (CPU driver) is run for each core. Most of the functionality covered inside of monolithic kernels is handled by code running in user space, either in specific services or inside of a Barrelfish/AOS library that is linked to all user programs. Barrelfish pushes the exokernel concept even more. A separate kernel is run on each core. CPU drivers can be used in homogeneous and heterogeneous environments. However, maintaining state of the operating system changes from maintaining state inside of a monolithic system to maintaining state in a distributed system using distributed algorithms instead of local ones. Thus, the architecture of Barrelfish is called a multikernel.
Capabilities
Manipulating the virtual address space inside of the user space leads to a critical question: How can the system assure that a user space process cannot manipulate the address space of another process (unless desired)? Barrelfish uses a partitioned capabilities system for almost all objects in the system. Capabilities are an old concept in computer science. They are of particular interest because they solve both, the naming problem and the access control problem at the same time.
Our tasks
We worked on a slightly modified skeleton version of Barrelfish that came without several key components (such as memory management, process spawning, core spawning, message passing, file system, network, name service, shell) for which we had to implement solutions.
We were fully free to pick solutions in the wide design space with one exception: we were not allowed to implement a fork mechanism (see Unix/Linux) to create new processes but use a spawn mechanism (e.g. used in Windows). There are many very good reasons for this in the context with Barrelfish. Additionally, it helped us to see differences between fork and spawn mechanisms (see also an interesting paper on fork).
Exposure to other radically different designs in Barrelfish (e.g. self-paging of virtual memory in user space) than the well known monolithic OS such as Linux lead to interesting insights and comparisons of these designs (advantages/disadvantages). Seeing and understanding the boot process (e.g. the moment when initial physical address space jumps to virtual address space; a magic flying carpet moment) had its own rewards.
Learned theory and skills from earlier classes came in very handy:
- Systems Programming and Computer Architecture (CASP)
- Operating Systems and Networks
- Embedded Systems: scheduling / dispatcher
- Compiler Design: assembly
- Formal Methods and Functional Programming (FMFP): establishing our own invariants for our memory manager
- Theoretical Computer Science: algorithm complexity, state machines
- Information Security: capabilities
- and much more
Barrelfish OlympOS
Following various milestones, we extended the initial skeleton with all the core components and services needed for an OS. We named crucial services and programs after gods and godesses of the classic Greek mythology. See documentation on my github page for details.
A core system (memory management, messaging service, core spawn, process spawn, serial I/O) were created in the group. Extensions (network I/O, FAT32 filesystem, shell, name service) were created in individual projects.
Name service Gaia
At the time when we all had to focus on our individual projects, our core system robustly provided the needed core features as defined (see description). However, there were some limitations to the system, some interconnected to each other.
- Messages could be sent from domains to domains running on the same and also different cores (messaging system), but capabilities could not yet be sent across cores in general.
- Services were provided by init (monitor/0) to all launched domains (monolithic). This was in contrast to our initial goal of distributed service providers.
- Dynamic late binding with distributed services needs a working name service, which became my individual project.
The official goals of my individual project were:
- define a name space for the services including rich meta information of the services
- design and implement a name service that allows dynamic late lookup and binding of services with other domains (processes)
- design and implement a user interface to access the information stored in the name service.
- optional, but also implemented: provide auto-detection whether a service is no longer running
Given the limitations of the core system, these additional tasks needed to be accomplished to make this work. This individual project involved changing many parts of the system, a bit more than initially anticipated.
- provide an extension to the existing messaging system to allow sending capabilities safely across cores; best leaving the current messaging API untouched and let the extension work completely transparently in the background
- distribute the services into different domains (all were still provided by monitor/0 or monitor/1 at that time)
- define minimum number of services that needed to be given to new domains at the “well known locations” in the spawn structure, while all the others could be linked dynamically
- solve the bootstrapping problem that came with this
It was my personal goal to provide the core functionality of this name service (registration, lookup and binding) as early as possible to my colleages so they could start using it when they aimed at testing the integration of their implementations of network and filesystem. Otherwise, temporary workaround solutions would have to be built first.
Additionally, dynamic lookup and binding of services was very easy to be used for my colleagues. Most complexity was hidden behind a very simple API. All re-routing of the messages needed to transport capabilities between processes running on different CPU cores, was transparent for the user of the messaging system.
It was very nice to see our Barrelfish OlympOS run performantly and robustly for the entire presentation despite showing quite complex tasks.
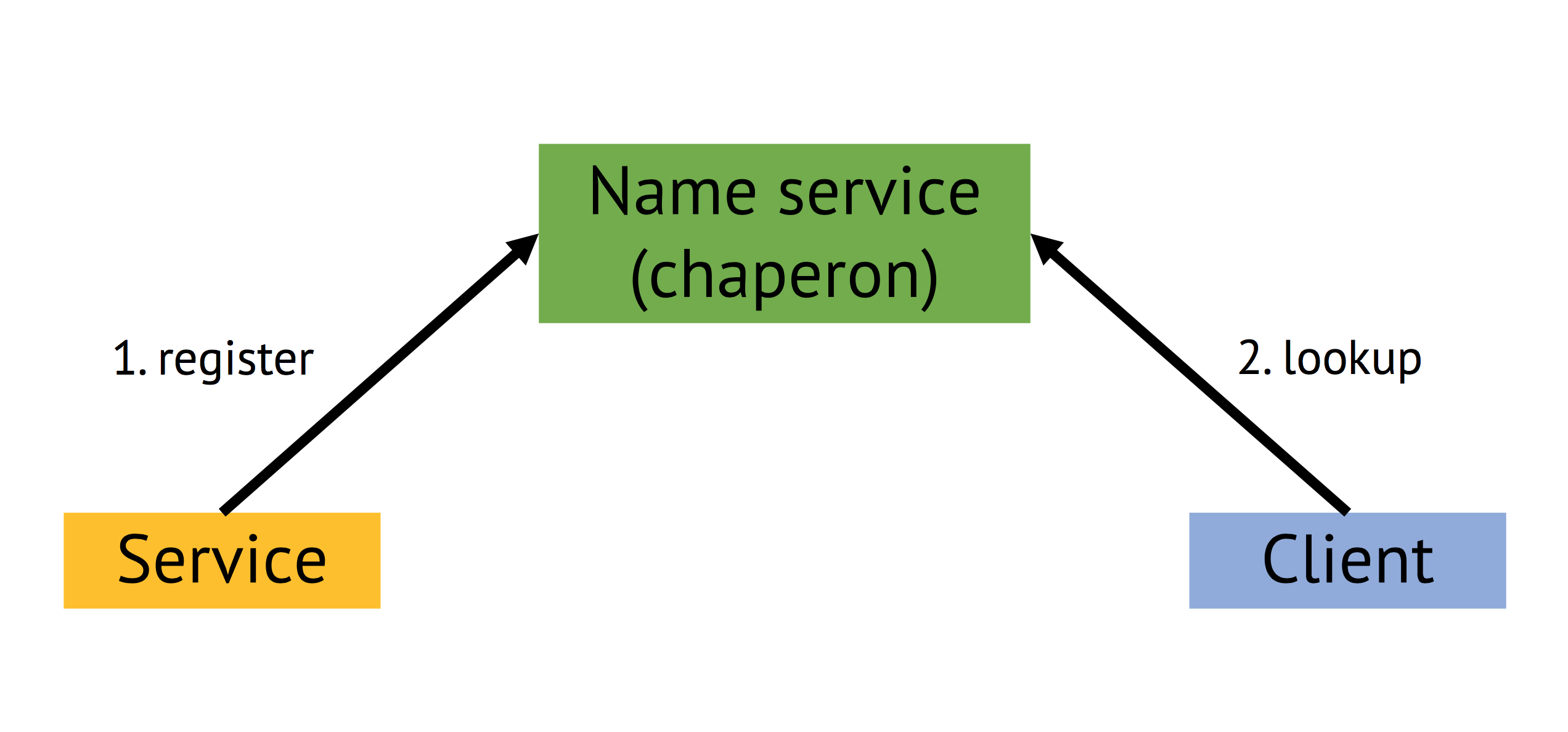
Gaia: service registration, lookup and late binding
Each process (a client) that wants to send messages to another process (a service, e.g. filesystem, serial I/O for terminal connection, memory system providing more RAM to processes, etc.) needs to know a message “endpoint” (EP) of the other process. Details of these EP vary a bit dependent on which of the implemented messaging systems is used. However, all of them basically represent a memory location with a capability as reference.
In the core system, all service EP were stored in pre-defined “well-known” locations, which works quickly for a very simple system but does not scale when more and more services need to be added. Thus, the name service provides a possibility to lookup running services, request new EP to establish a messaging connection (bind) under the additional difficulty that exchanging capabilities across cores is tricky based on limitations of the messaging options of the available kernel. This late binding is one key component for distributing and scaling of our OS variant.
| registration and lookup | late binding | re-routing |
|---|---|---|
 | 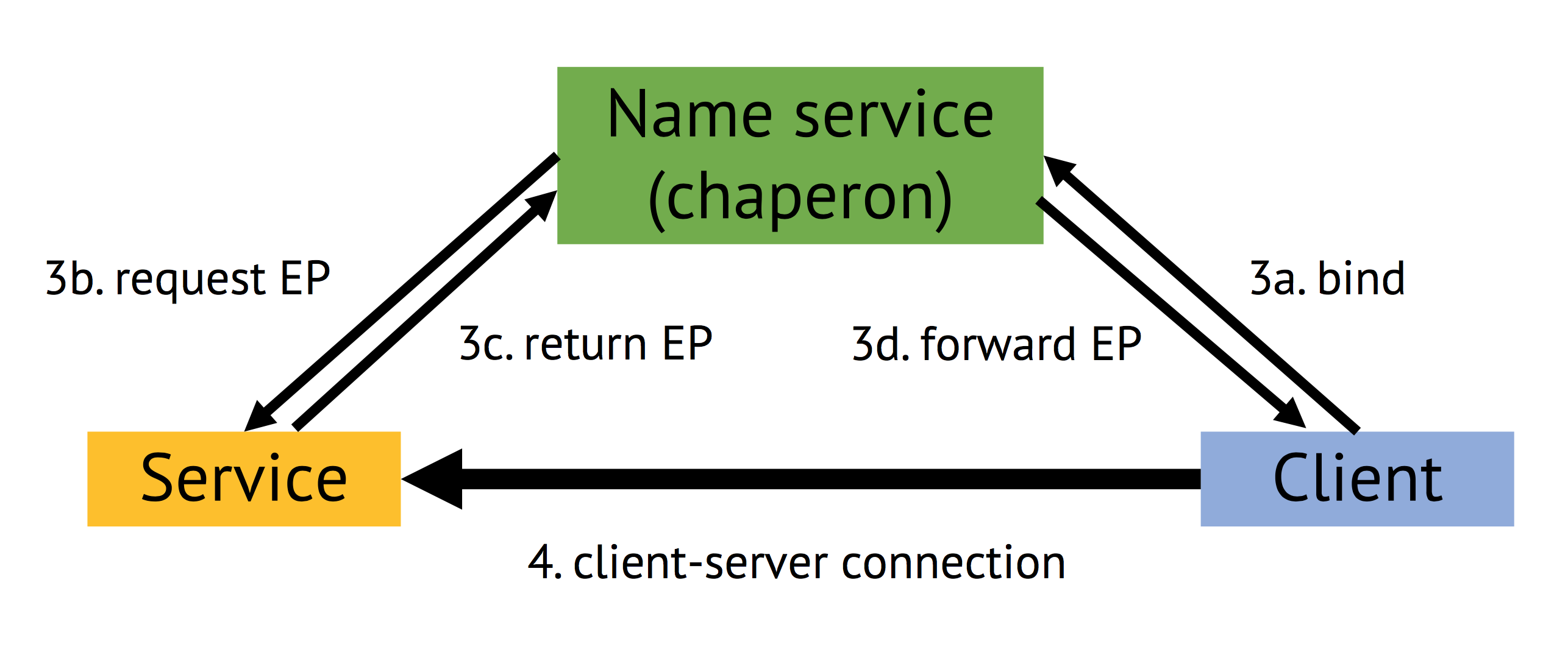 | 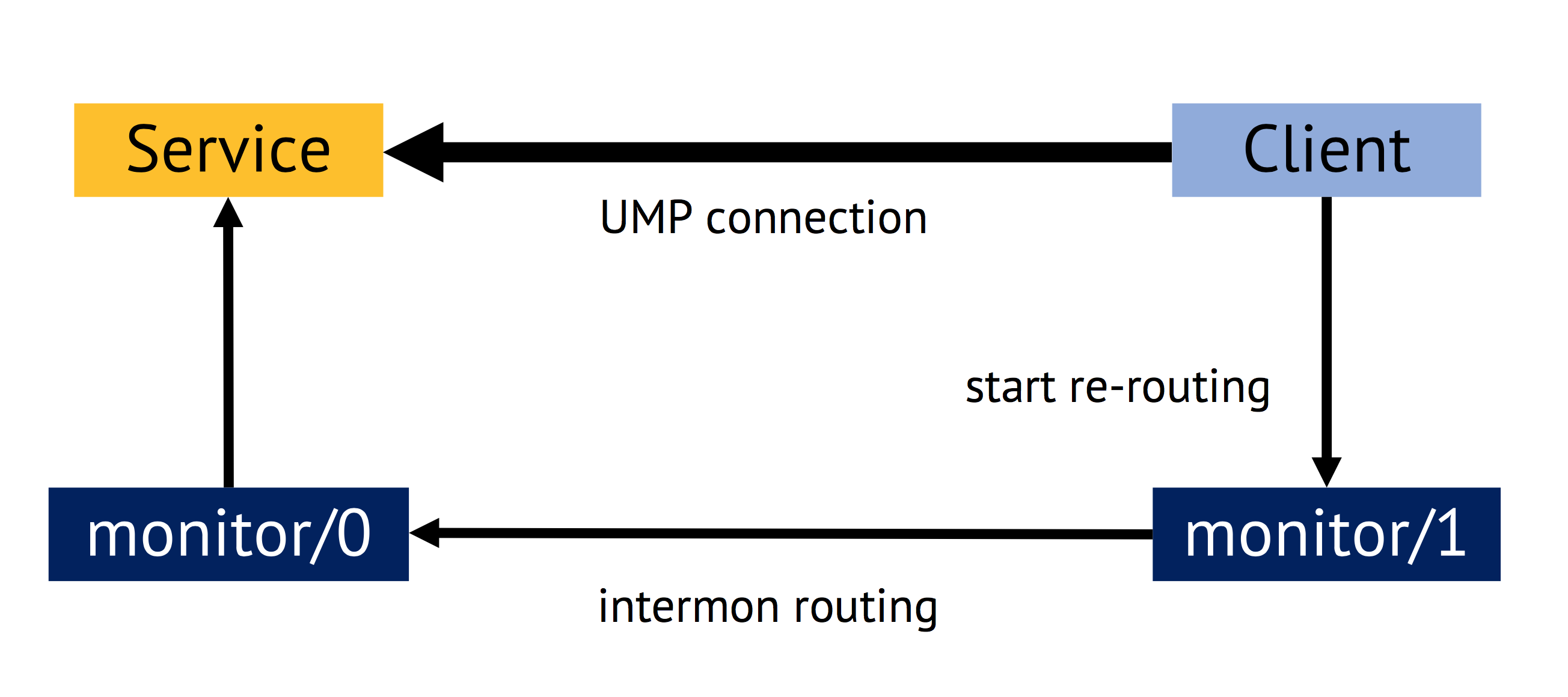 |
Sending capabilities across cores required an implementation of an automatic re-routing system of messages. Instead of using a direct connection (UMP) between processes running on different cores, messages transporting capabilities were re-routed through the monitor processes running on each core.
There is a monitor domain (process) for each core of the system spawned directly by the CPU driver (kernel) of this CPU core. Monitors have special privileges and must be considered to be part of the trusted computing base (TCB). We used these special privileges to transfer capabilities securely between arbitrary processes running on different cores. For this, an intermon service was introduced.
Documentation and code snippets
The project is documented in much more detail and with more explanations on my github page. This documentation includes a few code snippets for illustration:
- stack-trace: added C code that transforms the error information of the kernel (a program counter) into a full stack trace as seen e.g. in Java including runtime resolution of function names.
- look-ahead stack allocation: a very elegant solution to a spuriously occurring crashing bug during the vulnerable phase of deactivated dispatcher (scheduler) because we allowed our stacks to grow dynamically as needed. It comes with some detail information on the memory system implementation.
- boot LEDs: Some ARM assembly code that allowed us to use the LEDs of the board in diagnosing some spurious bugs while spawning the 2nd core of the ARM SoC of the Pandaboard.
- serializable key-value store implementation in C: To provide the required rich metadata functionality, a key-value store was used in the name service; the serialization feature simplified communication with the name service a lot.
Enjoy and feel free to contact me in case of questions.