
Studying Queueing Theory with a database middleware in a closed system
Queueing Theory was used in this student project to benchmark a self-built database middleware system in the Microsoft Azure cloud. Proper system analysis and bottleneck detection is crucial to improve distributed systems where the most benefit can be achieved. Queueing Theory has many practical applications in computer systems and real life. As often, learning a theoretical topic in combination with a practical project gives a much deeper understanding than just learning the theory.
In this Advanced Systems Lab (ASL) project a closed distributed database system was studied. It consists of multiple key-value stores (memcached servers), data and load generating clients (memtier_benchmark), and a self-written multi-threaded Java middleware application that was built following the specification in the project description. The middleware achieves load-balancing and data replication. The system was evaluated when deployed on virtual machines (VMs) in the Microsoft Azure cloud running Ubuntu.
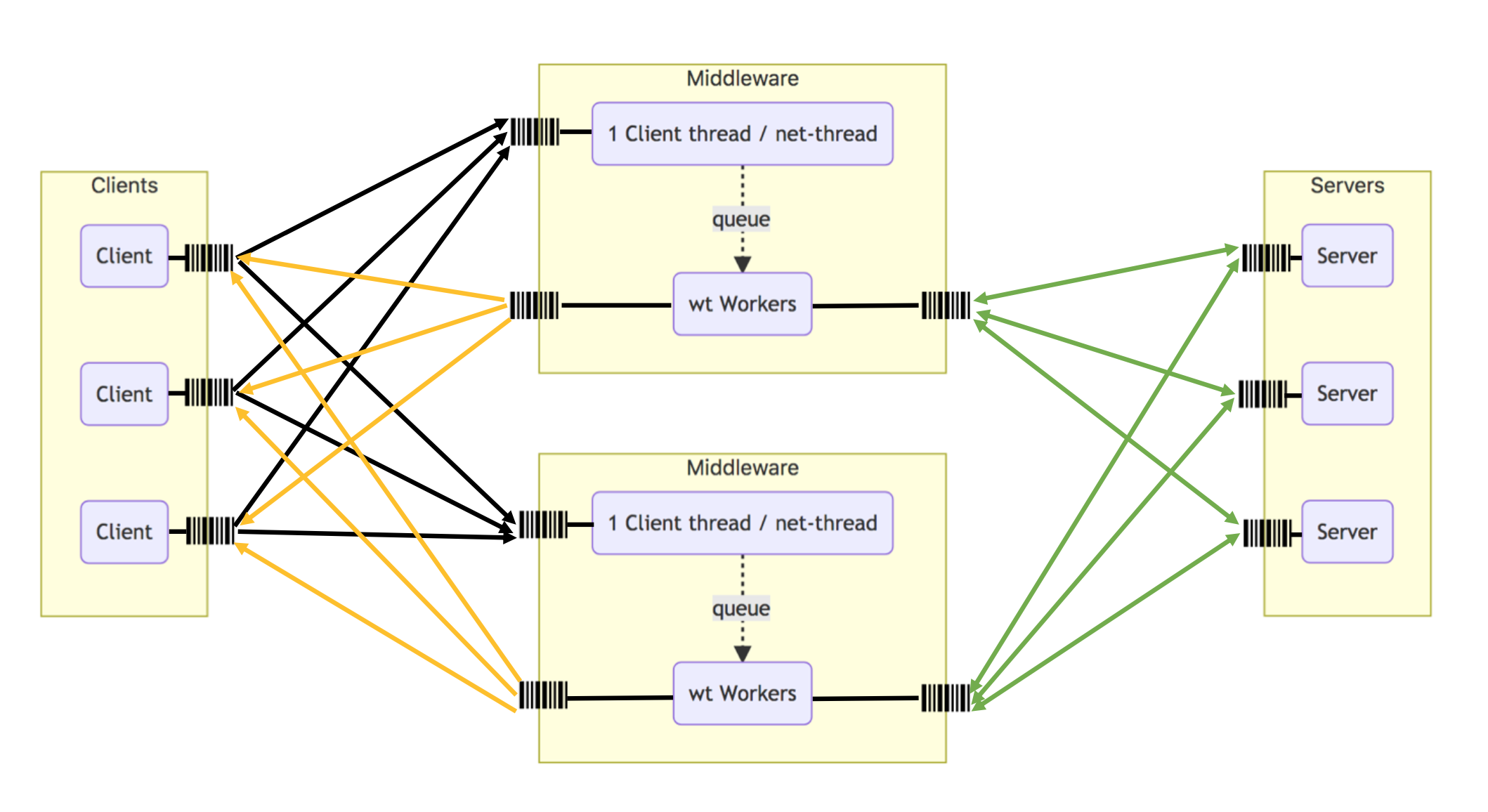
In experiments, the effect of various system configuration parameters were analyzed, such as adding a middleware to a base system, replication of data stores into multiple servers, or effect of sharding client requests for multiple data sets to different servers instead of forwarding the entire request to one of the servers.
Detailed benchmarking and analysis (e.g. operational laws, 2K experiment design) was used to detect the bottleneck in various configurations. Queueing theory was used to model the system and compare the various models with the real system. Many things were learned during this project. Unfortunately, the given project parameters were set that the results themselves were boring. Answers to several more interesting questions could not be reported in the report due to strict page limitation to 35 and many formally required tables/figures.
Developed data collection methods (minimally-interfering instrumentation and data collection, self documenting experiments, automatic meta-data embedding, slicing of the collected data tensors and creation of all tables and figures, etc.) simplified data analysis and have already shown to be useful for future projects. They showed to be very useful to handle the >500 MB (compressed) collected data.
Links